1、概述
嗨喽,大家好呀!我是简凡,一位游走于各互联网大厂间的新时代农民工。对于C端在线业务,服务的稳定性和吞吐量常常是评估一个系统的重要指标,所以本文将从以下4点进行展开,逐步讲解golang中如何进行性能优化。
- 为什么要做性能优化
- 性能优化基础
- 优化思路
- 常见的优化场景
2、性能优化的目的(Why?)
我们常常在以下时候考虑到性能优化:
- 日常优化系统:
- 接口相应时间优化,以满足对上游的SLA
- CPU优化,保证在线业务cpu idl处于一个较高水平,降低业务量突增对系统稳定性带来的冲击
- 内存优化,减少内存占用,释放多余的服务器资源
- 解决线上业务问题:
- 接口相应超时
- CPU利用率飙升
3、性能优化基础(What?)
3.1 性能优化指标
在Golang服务中,我们常常从以下4点触发去做服务的优化:
- CPU profile:报告程序的 CPU 使用情况,按照一定频率去采集应用程序在 CPU 和寄存器上面的数据
- Memory Profile(Heap Profile):报告程序的内存使用情况
- Block Profiling:报告 goroutines 不在运行状态的情况,可以用来分析和查找死锁等性能瓶颈
- Goroutine Profiling:报告 goroutines 的使用情况,有哪些 goroutine,它们的调用关系是怎样的
4. 性能分析过程(How?)
4.1 如何获取性能快照
golang中有两种类型的应用,工具性应用和服务型应用,工具性型应用的main函数仅一段时间,我们本地跑单元测试的性能测试其实原理就是应用的这种。服务型应用为长期存活的后端应用,例如RPC服务,HTTP服务,我们后端系统通常都是服务型应用。
4.1.1 工具型应用获取CPU快照
测试Demo如下,这里用了一个快排的例子,应用执行结束后,就会生成一个文件,保存了我们的 CPU profiling 数据。得到采样数据之后,使用go tool pprof工具进行 CPU 性能分析。
package main
import (
"math/rand"
"os"
"runtime/pprof"
"time"
)
func generate(n int) []int {
rand.Seed(time.Now().UnixNano())
nums := make([]int, 0)
for i := 0; i < n; i++ {
nums = append(nums, rand.Int())
}
return nums
}
func bubbleSort(nums []int) {
for i := 0; i < len(nums); i++ {
for j := 1; j < len(nums)-i; j++ {
if nums[j] < nums[j-1] {
nums[j], nums[j-1] = nums[j-1], nums[j]
}
}
}
}
func main() {
pprof.StartCPUProfile(os.Stdout)
defer pprof.StopCPUProfile()
n := 10
for i := 0; i < 5; i++ {
nums := generate(n)
bubbleSort(nums)
n *= 10
}
}这里使用的runtime/pprof这个分析工具,需要指定快照打印的位置,这里打印到标准输出了。可以会与程序中的打印冲突。我们可以自己实现写到文件中,这里可以用另一个开源工具替代github.com/pkg/profile,它会生成一个日志快照文件到临时目录。
package main
import (
"math/rand"
"github.com/pkg/profile"
"time"
)
func generate(n int) []int {
rand.Seed(time.Now().UnixNano())
nums := make([]int, 0)
for i := 0; i < n; i++ {
nums = append(nums, rand.Int())
}
return nums
}
func bubbleSort(nums []int) {
for i := 0; i < len(nums); i++ {
for j := 1; j < len(nums)-i; j++ {
if nums[j] < nums[j-1] {
nums[j], nums[j-1] = nums[j-1], nums[j]
}
}
}
}
func main() {
defer profile.Start(profile.MemProfile, profile.MemProfileRate(1)).Stop()
n := 10
for i := 0; i < 5; i++ {
nums := generate(n)
bubbleSort(nums)
n *= 10
}
}4.1.1 服务型应用CPU分析
如果你的应用程序是一直运行的,比如 web 应用,那么可以使用net/http/pprof库,它能够在提供 HTTP 服务进行分析。这样你的 HTTP 服务都会多出/debug/pprof endpoint,访问它会得到类似下面的内容:
package main
import (
"net/http"
_ "net/http/pprof"
)
func main() {
http.ListenAndServe("0.0.0.0:8000", nil)
}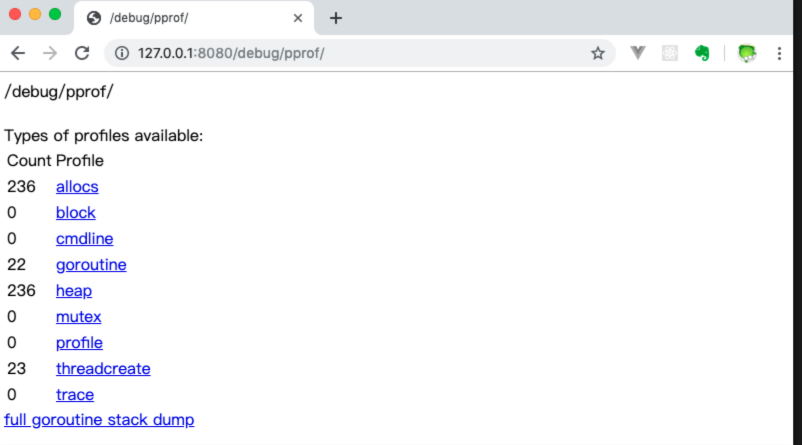
现在数据已经可以采集了,那如何获取快照呢?我们上一步的操作,在后台起了一个http server服务,我们直接点击ui中的链接就可以拿到内存快照了,例如点击profile,我们就可以拿到一个30s的CPU快照,是一个*.pb.gz类型的二进制文件,可用于我们后面的分析。
- /debug/pprof/profile:访问这个链接会自动进行 CPU profiling,持续 30s,并生成一个文件供下载
- /debug/pprof/heap: Memory Profiling 的路径,访问这个链接会得到一个内存 Profiling 结果的文件
- /debug/pprof/block:block Profiling 的路径
- /debug/pprof/goroutines:运行的 goroutines 列表,以及调用关系
4.2 go tool分析性能快照
不管是工具型应用还是服务型应用,我们使用相应的 pprof 库获取数据之后,下一步的都要对这些数据进行分析,我们可以使用go tool pprof命令行工具。
go tool pprof最简单的使用方式为:
go tool pprof [binary] [source]其中:
- binary 是应用的二进制文件,用来解析各种符号;例如:go tool pprof -http=:9999 /Users/xxxx/pprof/pprof.samples.cpu.001.pb.gz
- source 表示 profile 数据的来源,可以是本地的文件,也可以是 http 地址。此方式会在命令窗口中按照交互模式例如:go tool pprof http://127.0.0.1:8000/debug/pprof/profile
注意事项: 获取的 Profiling 数据是动态的,要想获得有效的数据,请保证应用处于较大的负载(比如正在生成中运行的服务,或者通过其他压测工具模拟访问压力)。否则如果应用处于空闲状态,得到的结果可能没有任何意义。
可以增加些参数来获取更多信息,例如:
# 我们想获取70s的内存快照,可以增加-seconds参数:
gotool pprof -seconds 70 http://127.0.0.1:8912/debug/pprof/profile
# 指定http接口,可以在ui上看到内存快照,参见本文4.2.2
gotool pprof -http=0.0.0.0:8234 http://127.0.0.1:8912/debug/pprof/profile4.2.1 直连服务分析
go tool + 线上服务http接口地址的方式:
go tool pprof http://127.0.0.1:8000/debug/pprof/profile执行上面的代码会进入交互界面如下:
runtime_pprof $ go tool pprof cpu.pprof
Type: cpu
Time: Jun 28, 2019 at 11:28am (CST)
Duration: 20.13s, Total samples = 1.91mins (568.60%)
Entering interactive mode (type "help" for commands, "o" for options)
(pprof)我们可以在交互界面输入top3来查看程序中占用 CPU 前 3 位的函数:
(pprof) top3
Showing nodes accounting for 100.37s, 87.68% of 114.47s total
Dropped 17 nodes (cum <= 0.57s)
Showing top 3 nodes out of 4
flat flat% sum% cum cum%
42.52s 37.15% 37.15% 91.73s 80.13% runtime.selectnbrecv
35.21s 30.76% 67.90% 39.49s 34.50% runtime.chanrecv
22.64s 19.78% 87.68% 114.37s 99.91% main.logicCode其中:
- flat:当前函数占用 CPU 的耗时
- flat:: 当前函数占用 CPU 的耗时百分比
- sun%:函数占用 CPU 的耗时累计百分比
- cum:当前函数加上调用当前函数的函数占用 CPU 的总耗时
- cum%:当前函数加上调用当前函数的函数占用 CPU 的总耗时百分比
- 最后一列:函数名称
在大多数的情况下,我们可以通过分析这五列得出一个应用程序的运行情况,并对程序进行优化。
我们还可以使用list 函数名命令查看具体的函数分析,例如执行list logicCode查看我们编写的函数的详细分析。
(pprof) list logicCode
Total: 1.91mins
ROUTINE ================ main.logicCode in .../runtime_pprof/main.go
22.64s 1.91mins (flat, cum) 99.91% of Total
. . 12:func logicCode() {
. . 13: var c chan int
. . 14: for {
. . 15: select {
. . 16: case v := <-c:
22.64s 1.91mins 17: fmt.Printf("recv from chan, value:%v\n", v)
. . 18: default:
. . 19:
. . 20: }
. . 21: }
. . 22:}通过分析发现大部分 CPU 资源被 17 行占用,我们分析出 select 语句中的 default 没有内容会导致上面的case v:=<-c:一直执行。我们在 default 分支添加一行time.Sleep(time.Second)即可。
4.2.2 快照文件+图形化工具
这种快照文件的方式好处是更加直观,可以通过图形化界面来分析:
想要查看图形化的界面首先需要安装 graphviz 图形化工具。Mac:brew install graphviz
接下来,可以用 go tool pprof 分析这份数据
go tool pprof -http=:9999 cpu.pprof访问 localhost:9999,可以看到这样的页面: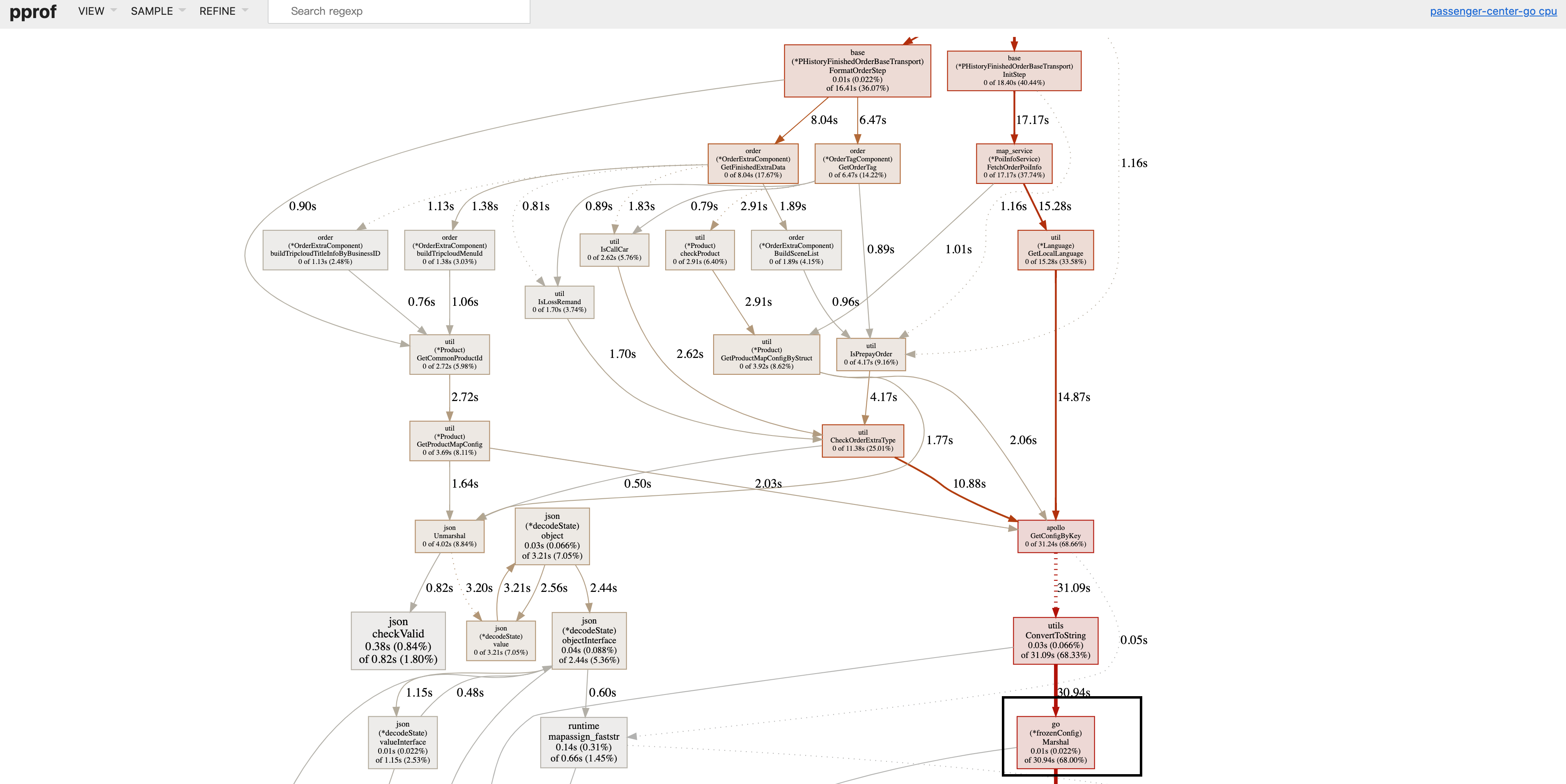
当然我们还可以选择VIEW,然后看火焰图: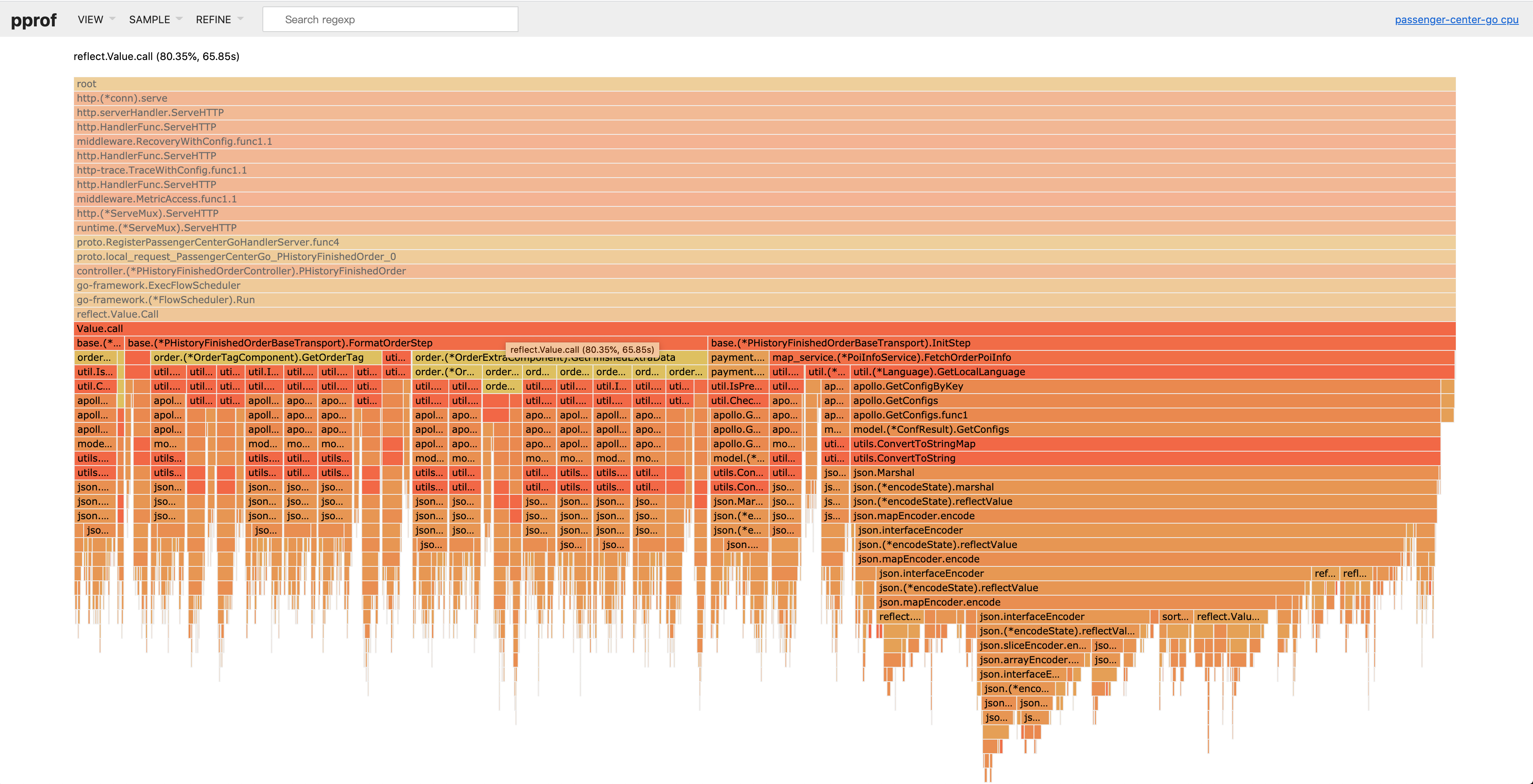
至此,我们就成功的获取了每个函数占用的CPU时间了,下面就可以对占用较长的函数(平顶山部分)进行优化了。
5、常见性能优化手段
5.1 使用高效的性能包
5.1.1 Json解析
我们将Json数据存放到Redis时,取出时需要将其解析为Struct,但go官方自带的库性能较差,所以常常出现瓶颈,可选择github.com/json-iterator 替换标准库的 encoding/json(该库主要的优化手段详见:http://jsoniter.com/benchmark.html#optimization-used)。 json-iterator 宣传的性能如下图: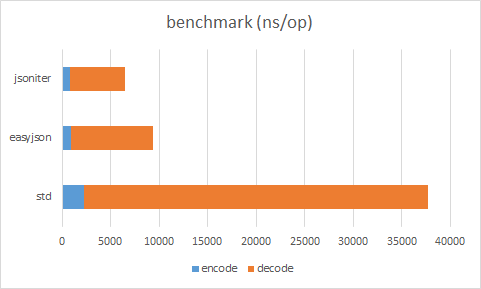
5.1.2 深拷贝
还有时我们需要在项目中使用到深拷贝的场景,可以参考这篇文章,深拷贝性能对比:https://www.yuque.com/jinsesihuanian/gpwou5/xg20gn。
5.2 空间换时间
- 对于常见的Json解析问题,Redis大key问题,我们可以进行多级缓存,将Redis中的大key数据缓存到内存中,这里别忘了考虑带来的缓存一致性问题。
- 对于一些map,slice,尽量在初始化时指定大小,减少内存的重新分配
5.3 字符串拼接
字符串的拼接优先考虑bytes.Buffer。由于string类型是一个不可变类型,但拼接会创建新的string。GO中字符串拼接常见有如下几种方式,对性能要求很高的服务尽量使用bytes.Buffer进行字符串拼接
- string + 操作 :导致多次对象的分配与值拷贝
- fmt.Sprintf :会动态解析参数,效率好不哪去
- strings.Join :内部是[]byte的append
- bytes.Buffer :可以预先分配大小,减少对象分配与拷贝
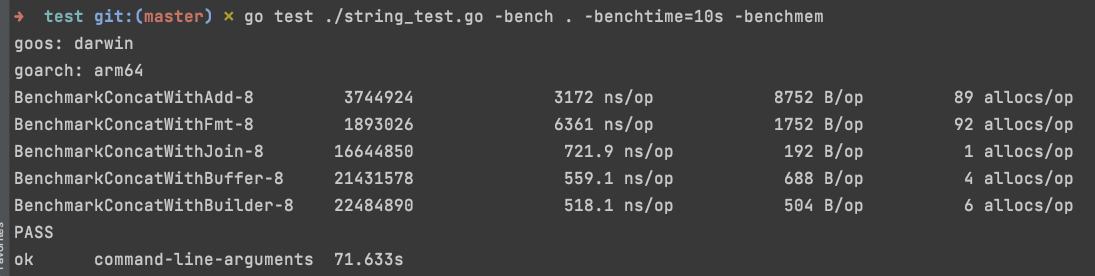
使用strconv包替代fmt.Sprintf的格式化方式,性能比对见:https://www.cnblogs.com/yumuxu/p/4077234.html
5.4 异步处理
既然选用了Golang,自然要用到它简单易用的并发机制啦,我们可以把一些不影响主流程的操作完全可以异步化,例如发送邮件、写日志等。可以把一些业务场景并行处理,例如你要一次性读取多个文件。
6、总结
代码层面的优化,是 us 级别的,而针对业务对存储进行优化,可以做到 ms 级别的,所以优化越靠近应用层效果越好。对于代码层面,优化的步骤是:
- 利用压测工具模拟场景所需的真实流量。压测工具推荐使用 https://github.com/wg/wrk 或 https://github.com/adjust/go-wrk
- pprof 等工具查看服务的 CPU、MEM 耗时
- 锁定平顶山逻辑,看优化可能性:异步处理,空间换时间,使用高性能包 等
- 局部优化完写 benchmark 工具查看优化效果
- 整体优化完回到步骤一,重新进行 压测+pprof 看效果,看耗时能否满足要求,如果无法满足需求,那就换存储吧~😭
后续我会给大家出一篇关于Golang服务的代码开发建议,我们下期见,Peace😘
我是简凡,一个励志用最简单的语言,描述最复杂问题的新时代农民工。求点赞,求关注,如果你对此篇文章有什么疑惑,欢迎在我的微信公众号中留言,我还可以为你提供以下帮助:
- 帮助建立自己的知识体系
- 互联网真实高并发场景实战讲解
- 不定期分享Golang、Java相关业内的经典场景实践
我的博客:https://besthpt.github.io/
微信公众号:”简凡丶”




